HBase的架构
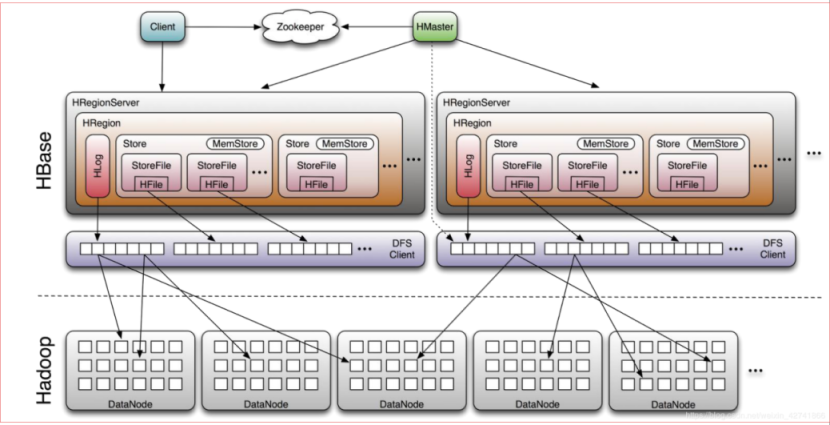
HMaster:
负责HBase中table和region的管理,regionserver的负载均衡,region分布调整,region分裂以及分裂后的region分配,regionserver失效后的region迁移等。
Zookeeper:
存储root表的地址和master地址,regionserver主动向zookeeper注册,使得master可随时感知各regionserver的健康状态。避免master单点故障。
RegionServer:
HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
HRegion Server内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个Region,Region中由多个Store组成。每个Store对应了Table中的一个Column Family的存储,即一个Store管理一个region上的一个列簇。每个Store包含一个MemStore和0到多个StoreFile。Store是HBase存储核心,由MemStore和StoreFiles组成。
MemStore:
MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile), 当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。
HBase中的rowkey以及热点问题
HBase热点现象:
检索hbase的记录首先要通过rowkey来定义数据行,当大量的client访问hbase集群的一个或少数几个节点,造成少数region server的读/写请求过多,负载过大,最终导致单个主机负载过大,引来性能下降甚至region不可用。
热点产生原因:
有大量连续编号的rowkey,导致大量记录集中在个别region。
避免热点方法:
- 加盐:在rowkey的前面增加随机数。此方式适用于将hbase作为海量存储数据而不频繁查询的业务场景。
- 哈希:Hash散列,将数据打乱。
- 反转:包括rowkey字段反转和时间戳反转。例如联通就是这样。时间戳加手机号20181123_13191***,引入一张索引表存储以上字段,hbase中的rowkey则是以上字段的反转。
rowkey设计原则:
- rowkey唯一原则
- rowkey长度原则:
二进制数,可以是任意字符,最多给到64kb,建议10-100个字节,但是越短越好,最好不要超过16个字节。原因如下:
- 数据都是存在Hfile中按照key-value进行存储的,如果rowkey超过了100个字节,1000万条数据,100*1000万=10亿个字节,约为1G,极大浪费Hfile的存储资源。
- memstore将缓存部分数据到内存,如果rowkey过大,内存的有效利用率就会降低,从而降低检索效率。
HBase的应用场景
- 需对数据进行随机读写操作;
- 大数据上高并发操作,比如每秒对PB级数据进行上千次操作;
- 读写访问均是非常简单的操作。
HBase的寻址过程(读写数据过程)
client–zookeeper–root–meta–region
客户端先通过zookeeper获取到root表的地址,通过root表获取.meta表的地址,.meta表上记录了具体的region的地址。

